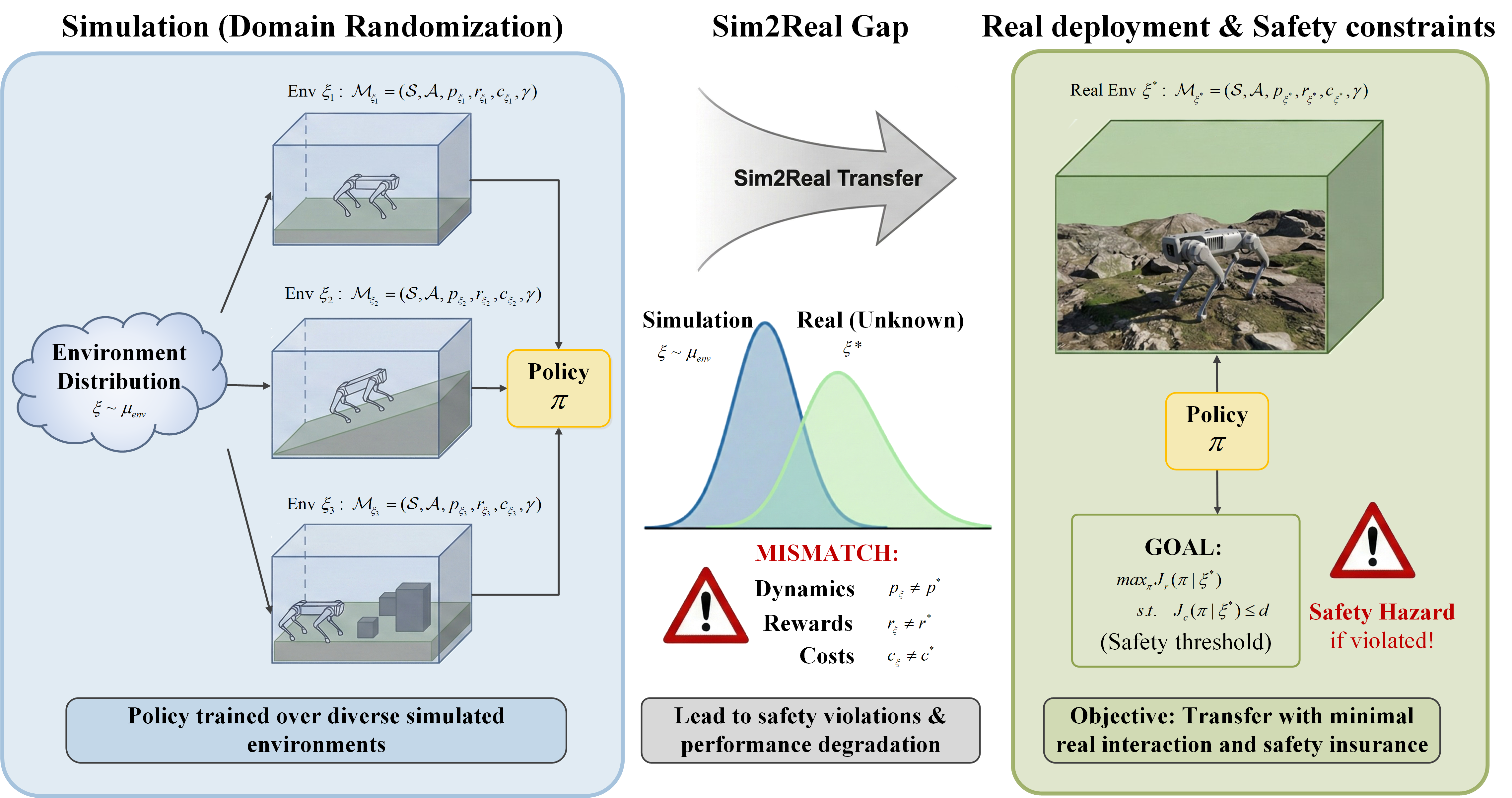
Due to limited resources and public safety concerns, deep reinforcement learning (RL) agents for many cyber-physical systems (e.g., autonomous vehicles) are first trained in simulators. However, when deployed in real world environments, they often suffer from performance degradation or safety violations because of the inevitable Sim2Real gap. Existing zero-shot approaches, such as robust safe RL and domain randomization, mitigate this issue but typically at the cost of degraded performance or residual safety risks when experiencing unmodeled system dynamics. To address these limitations, we propose a novel reinforcement learning framework that enables safe and efficient policy transfer via probabilistic latent embeddings and dynamic policy adaptation. We consider a family of Constrained Markov Decision Processes (CMDPs) under different environment contexts. By leveraging latent context variable in meta-RL, the proposed framework infers the latent representation of the environment from simulated experiences. Furthermore, it incorporates a distributional RL formulation, which allows risk levels of the deployed policy to be adjusted dynamically, based on the estimation accuracy of the latent context variable. This strategy promotes safety at the early deployment stage and improves efficiency through fast policy adaptation under the Sim2Real gap.

Framework overview of the proposed approach.
We introduce an encoder that extracts salient environment-specific information, enabling the learned policy to condition its actions on the underlying environment (Section 4.1). In addition, distributional reinforcement learning is employed to characterize the distributions of both rewards and costs under the latent information (Section 4.2 and 4.3), allowing risk level to be adjusted with latent context variable adaptation (Section 5.1). A safety upper-bound is then developed (Section 5.2) and the agent is proven to be safe under dynamic adaptation of risk-sensitive policy (Section 5.3 and 5.4). Together, these components enable safe and effective policy transfer with limited real-world interactions under the Sim2Real gap.

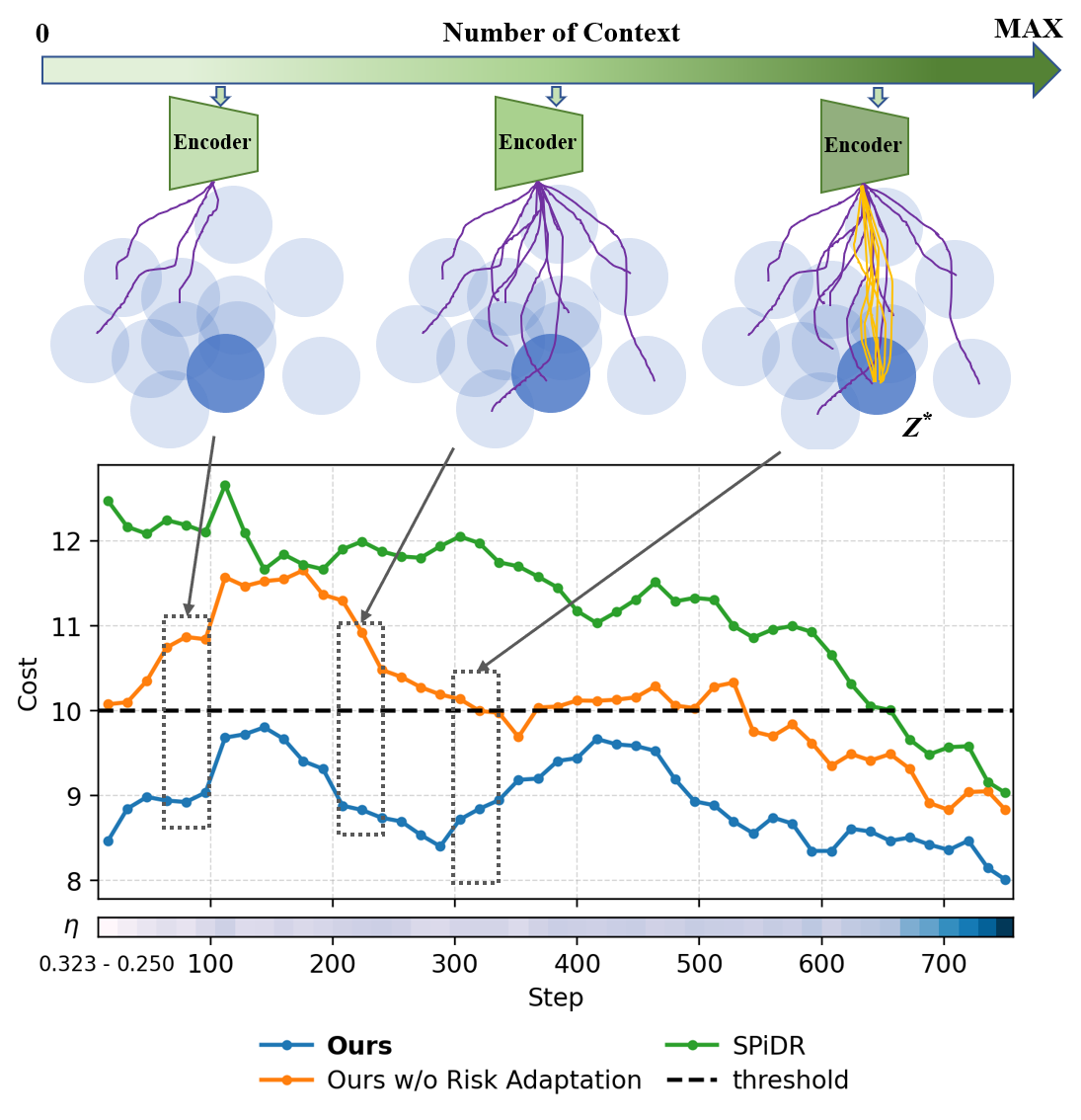
Demonstration of our proposed method for PointGoal2 task.
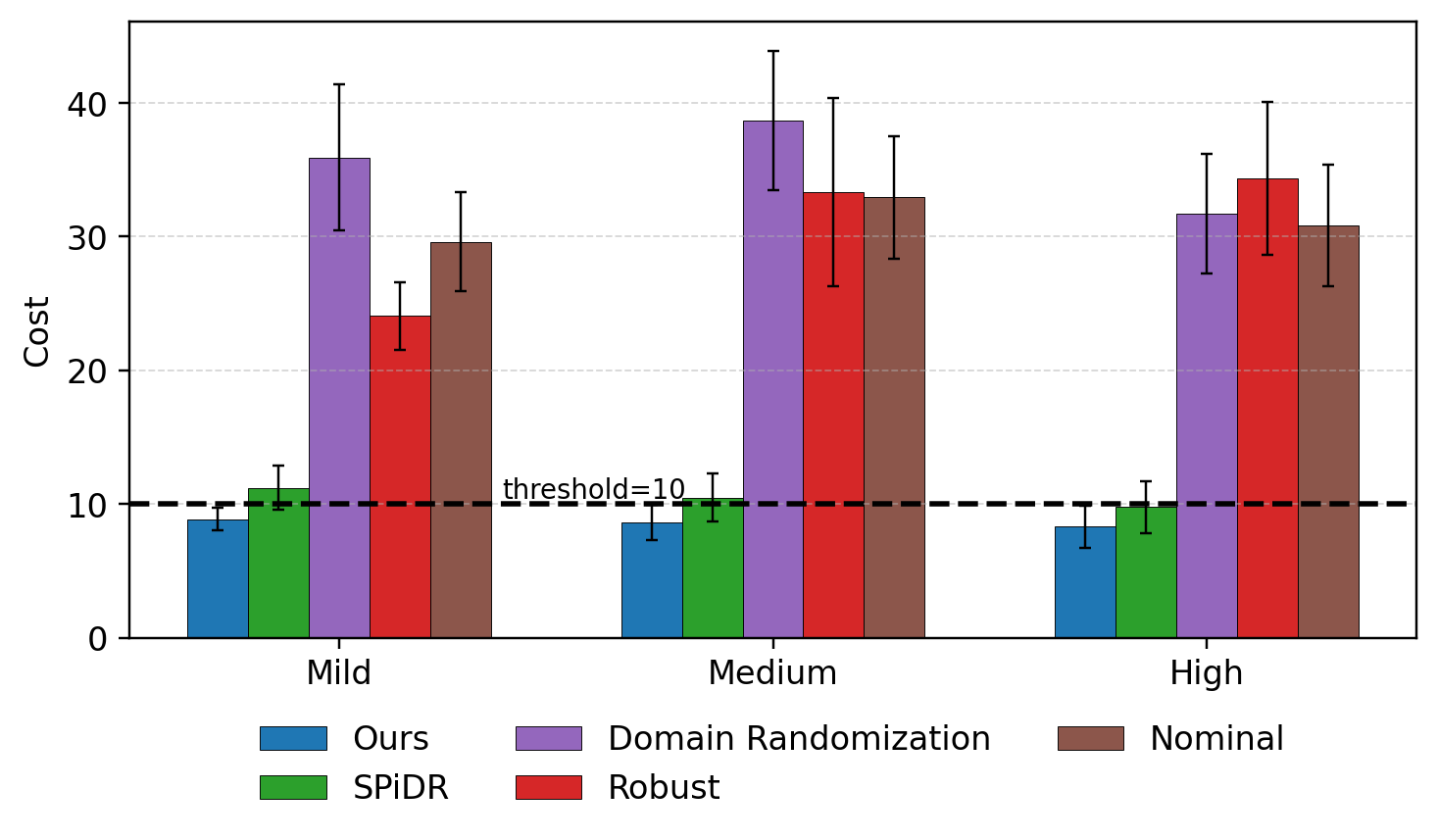
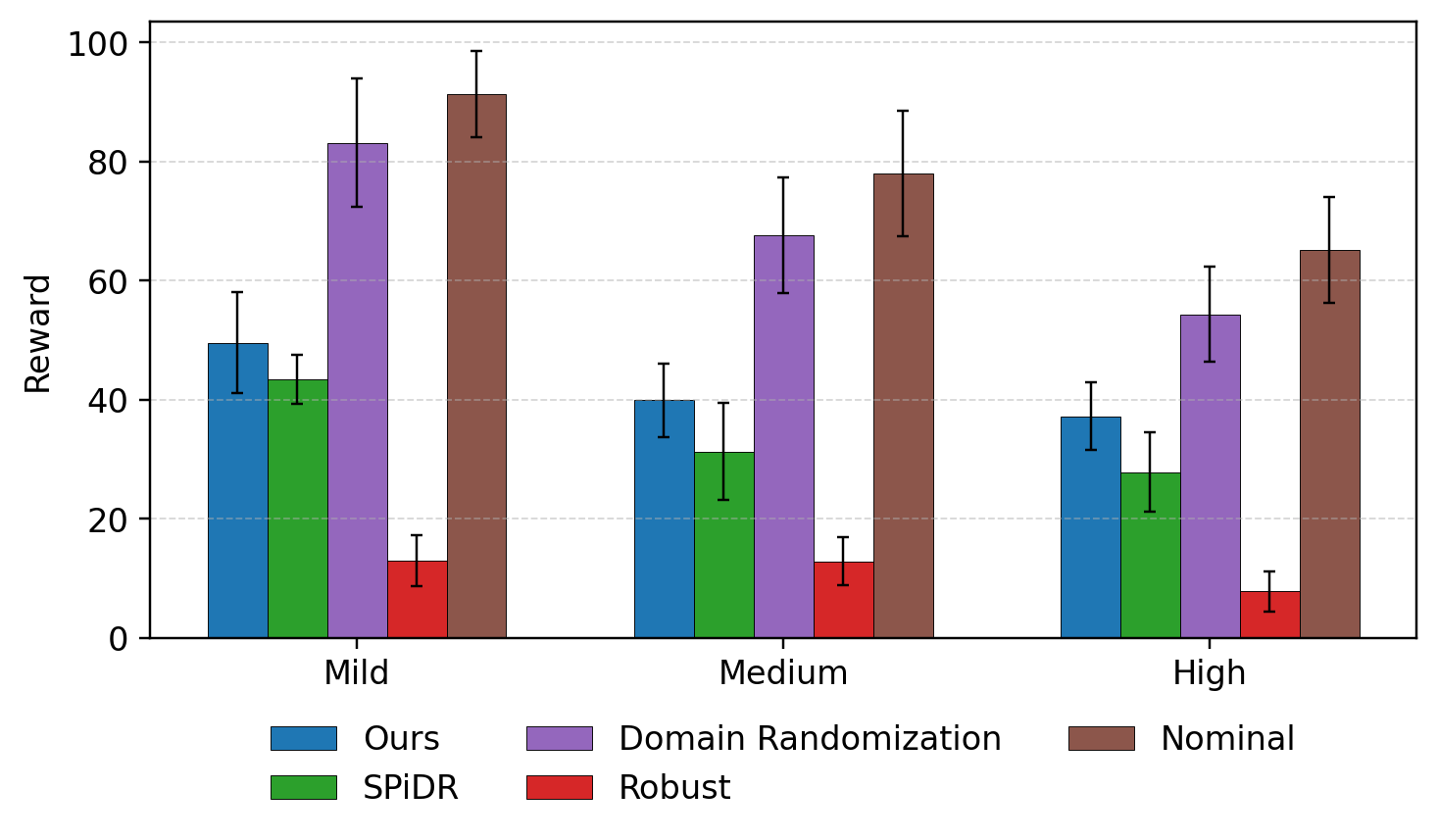
During training, all methods successfully learn to reach the goal without violating the cost constraints. In deployment, however, a clear performance divergence emerges. Nominal, Domain Randomized, and Robust RL baselines achieve high rewards but suffer from severe cost violations, indicating limited safety in the deployment environment with Sim2Real gap. In contrast, both SPiDR and our method exhibit conservative behaviors and have substantially lower costs, at the expense of lower rewards. This reward–cost trade-off is expected in both tasks, where more cautious navigation leads to better hazards avoidance in unseen environments in the first task, and more conservative AV speed-control reduces the risk of rear-end collisions in the second task. Notably, compared to SPiDR, our method achieves a more favorable trade-off by attaining lower deployment costs while simultaneously achieving higher rewards.
@inproceedings{han2026transferable,
title = {Transferable Reinforcement Learning via Probabilistic Latent
Embeddings and Dynamic Policy Adaptation for Sim-to-Real Deployment},
author = {Han, Gengyue and Feng, Yiheng},
booktitle = {Proceedings of the 43rd International Conference on
Machine Learning (ICML)},
year = {2026},
publisher = {PMLR},
address = {Seoul, South Korea}
}